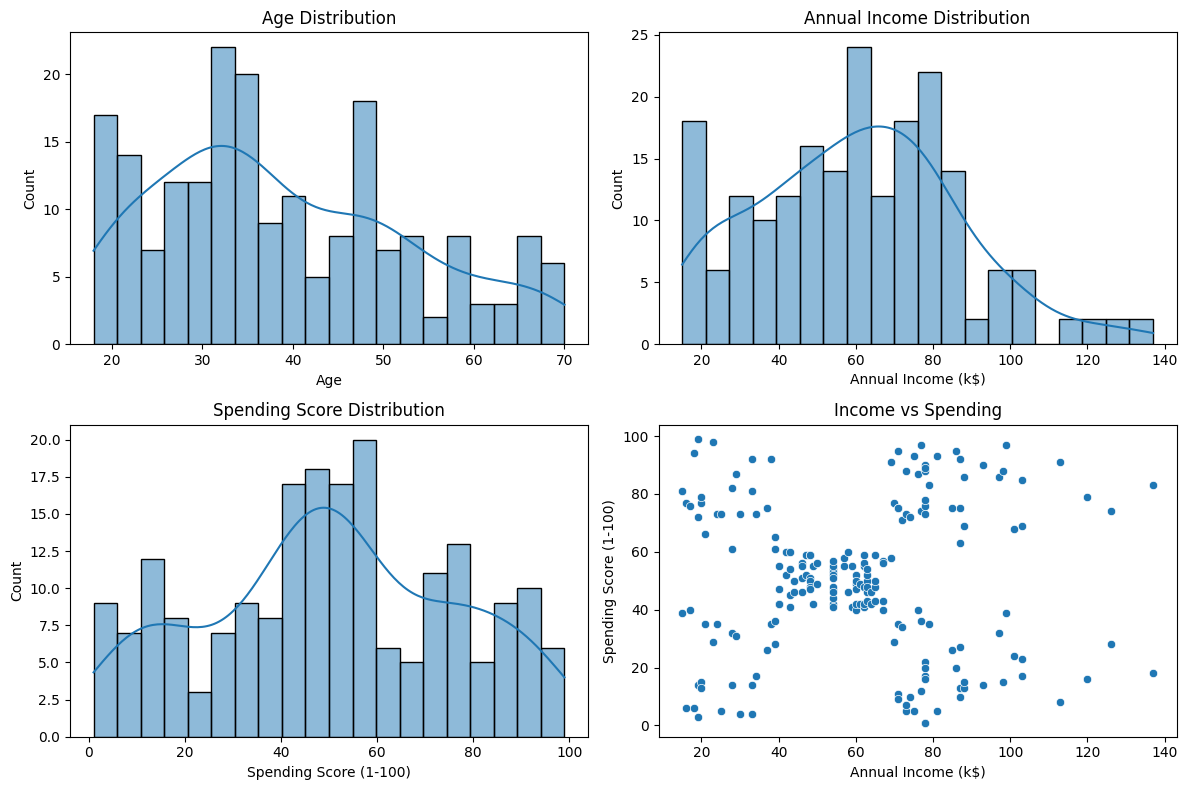
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
sns.histplot(clean_data["Age"], bins=20, kde=True, ax=axes[0, 0])
axes[0, 0].set_title("Age Distribution")
sns.histplot(clean_data["Annual Income (k$)"], bins=20, kde=True, ax=axes[0, 1])
axes[0, 1].set_title("Annual Income Distribution")
sns.histplot(clean_data["Spending Score (1-100)"], bins=20, kde=True, ax=axes[1, 0])
axes[1, 0].set_title("Spending Score Distribution")
sns.scatterplot(data=clean_data, x="Annual Income (k$)", y="Spending Score (1-100)", ax=axes[1, 1])
axes[1, 1].set_title("Income vs Spending")
plt.tight_layout()
plt.show()